

Together, we will take a look at the benefits of Splunk in Docker (and containerization in general) that allow you to quickly and repeatably create a Splunk environment that has the correct architecture, the apps you need, and the conf files you need to mimic any kind of production Splunk use case.
Have you ever been hindered when making improvements to your Splunk apps and dashboards because you can’t “tinker” in prod? Using Splunk in Docker containers can help you circumvent that issue by creating a prod-like environment right from the comfort of your own laptop.
What is Docker?
Docker is a daemon used to create and manage containers. Containers are an alternate approach to virtualization, opposed to virtual machines (VMs). While VMs are essentially their own complete computer on a hypervisor, only sharing resources like storage and compute, containers tend to focus on a singular application or process with guest OS and shared kernel.
Splunk has been supporting the container model of virtualization for some time now. There is a repository on their Github for maintaining docker images here: docker-splunk. The automation capabilities are fueled by Splunk-Ansible, which makes it a breeze to spin up all kinds of architectures.
The Benefits of Splunk in Docker
The combination of the lower resource cost of containers and the automation capabilities of Splunk-Ansible enable the creation of entire Splunk environments in mere minutes. You are able to use containers for Forwarders, dev environments, and even deploy Splunk in Kubernetes through the use of Splunk Operator for Kubernetes.
Being able to spin up any kind of Splunk environment in a quick and repeatable way through automation is a major enabler for Splunkers. You are able to have your own ecosystem for testing and tinkering with data on your laptop. You can perform restarts and potentially destructive commands without worrying about impacting other users on the system, and you are able to work through disaster scenarios and failovers safely outside of production.
Splunk docker allows user to easily switch between different versions of Splunk by simply updating the image tag and re-upping the container, allowing users to test for regression and experiment with new features ahead of your production cluster(s) getting updated.
Forwarder deployment can be tricky, especially when you are trying to manage extra dependencies like python or other tools not found on the system by default, or in the universal forwarder binaries directory. One can easily get all of those dependencies and miscellaneous .conf files in a container based on Splunk’s image ensuring it will always have what it needs despite what users may be doing with applications on that system.
Let’s look at a more practical example: Say you have a shared Linux server that has a lot of users. You set up Splunk Universal Forwarder and have a few TA’s to help you get exactly what you want log-wise. Let’s say those TA’s are out of date and still based on python 2.7. That box now must keep an end of life version of Python on it, just because logging solution needs it. If we move those dependencies into containers then you only need to have Docker on the box running your UF container and you’re good to go. The admin of that box could uninstall python and it won’t affect your work, because you are still getting your logs.
Kubernetes is a container orchestration system. It is incredibly useful for deploying containers in a safe and scalable way. If your organization is already using Kubernetes, you should definitely look into Splunk Operator. It takes the speed and ‘infrastructure as code’ approach to Splunk environment creation previously mentioned and enables management of resource consumption on production instances.
How to Spin Up Your First Splunk Container
Let’s get started and get Docker installed. Now we can spin up our first Splunk container. You can follow along with Kinney Group Engineer Troy Wiegand here on our YouTube channel: https://youtu.be/UnbCSMOV7Hs
You’ll want to run `docker pull splunk/splunk:latest`. This will confirm that we have docker installed and the docker daemon is running correctly.
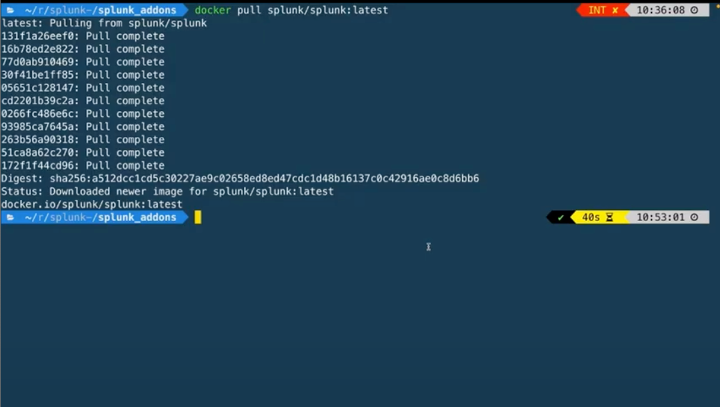
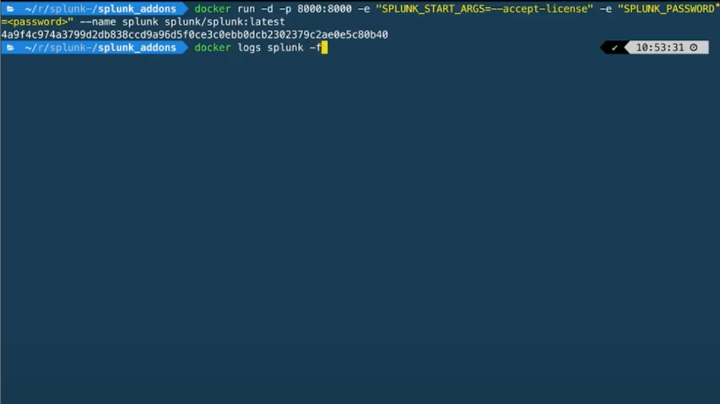
Now we can run `docker run -d -p 8000:8000 -e “SPLUNK_START_ARGS=–accept-license” -e “SPLUNK_PASSWORD=changeme” –name splunk splunk/splunk:latest` This will run in the background as the -d flag is set. We can peek in on the ansible log output of Splunk getting set up by running `docker logs splunk -f`
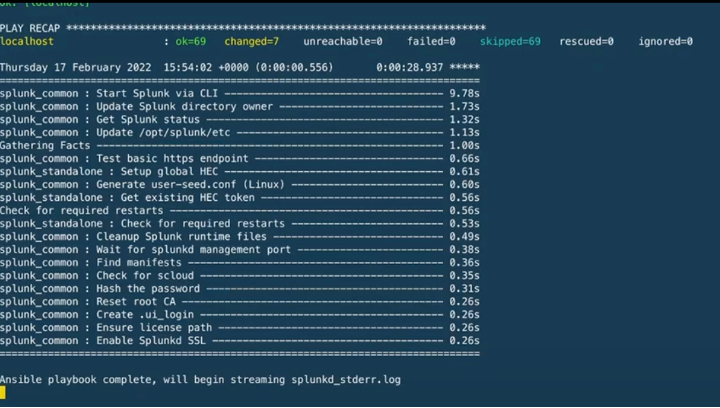
We will know that the Ansible run is complete when we see this output and the phrase “Ansible playbook complete”
We can now use a browser to navigate to [<http://localhost:8000>](<http://localhost:8000>) and log into our Splunk instance with the username `admin` and password `changeme`:
Use Cases
You can watch Kinney Group’s Splunk Containerization series which examines a number of use cases including installing apps, editing conf files, using Ansible Post Tasks to run searches and setting up HEC endpoints, and setting up Forwarder Images.
Conclusion
Using Splunk in Docker containers is a powerful tool that allows users to easily use code to spin up complicated Splunk infrastructure quickly. We went through the process of getting started with our first container and brainstormed some radical applications of the technology. You can watch our video series for a more in-depth guide to some of these use cases.
If you found this helpful…
You don’t have to master Splunk by yourself in order to get the most value out of it. Small, day-to-day optimizations of your environment can make all the difference in how you understand and use the data in your Splunk environment to manage all the work on your plate.
Cue Atlas Assessment: Instantly see where your Splunk environment is excelling and opportunities for improvement. From download to results, the whole process takes less than 30 minutes using the button below:



