

What is a knowledge object in Splunk?
Splunk knowledge objects are a set of user-defined searches, fields, and reports that enrich your data and give it structure. Basically, if you’re using Splunk, you’re using one very large knowledge object. With those knowledge objects, you can share them with other Splunk users, and include tags, events, reports, and alerts to organize and maintain your data.
There are several types of knowledge objects. Together these knowledge objects make up apps, and knowledge objects that service apps are called add-ons.
The Basics of Splunk Knowledge Objects
A knowledge object could be a piece of a search or a piece of data being ingested. It could also just be a group of data. When defining your knowledge objects, ask yourself, “What do I want Splunk to show me?”
To better identify your data, utilize your field extraction to pull from the data coming in. Let’s use the example of the identifier, “transaction ID.” You want to see all information relevant to the transaction ID extracted. To start, you create a field extraction around the knowledge object, transaction ID, and now you can search for that specific set of information.
Knowledge objects exist in the deployment, indexers, search heads, saved searches, and any other user-defined data with your Splunk instance. You can reference a knowledge object any time you’re trying to isolate down your data to a refinement point.
What are all of the Splunk Knowledge Objects?
- Index: A collection of data that is searchable and that can be retrieved using Splunk’s search language. Data is stored in indexes according to a set of rules and configurations.
- Source types: Labels that help Splunk determine the format of incoming data. Source types determine how data should be parsed and interpreted, allowing Splunk to extract fields and transform the data.
- Fields: Key-value pairs that contain specific data values extracted from events. Fields can be created automatically or defined manually by users. To create a field manually, you can use the Fields menu to create a new field and define its attributes.
- Search-time field extractions: configurations that allow users to create new fields based on the content of existing fields. They can be defined through configuration files.
- Lookups: Tables of data used to add context to events or map fields to different values. They’re typically created from CSV files or databases and can be used in searches and visualizations.
- Tags: Labels that can be applied to events, fields, or sources to categorize and group them. Tags can be created manually or defined through search-time extractions.
- Event types: Named collections of events that share similar characteristics or properties. Their purpose is to simplify searches, provide a higher level of abstraction, and help with reporting and alerting.
- Alerts: Configurations that trigger an action when a specific condition is met, specifically: sending notifications or running scripts.
- Reports: Saved searches that are scheduled to run at specific intervals and generate visualizations or summaries of data.
- Dashboards: Customizable displays that show real-time or historical data in the form of charts, tables, or other visualizations.
What are Knowledge Object tags?
Tags can help you centralize the naming conventions behind your data and knowledge objects. Below is an example of how this works.
How Splunk Knowledge Objects Work
For this example, we’ll use transaction ID. I’ve. In this scenario, you have multiple streams of data coming in.
Step 1: The transaction ID comes in through the firewall, hits the web server, goes into the database, and then transfers back through.
Step 2: If you have a transaction ID throughout that stream, you can tag each knowledge object at each index point.
Because your firewall is the one sending data in, you’ll want to tag your transaction ID within that point.
On your web server, you can tag that knowledge object with the same transaction ID.
The same goes for your database.
Step 3: Now, when you search on that transaction ID, Splunk will pull up that transaction ID for all of those data inputs.
Note: To maintain a common naming convention, tag your data early on.
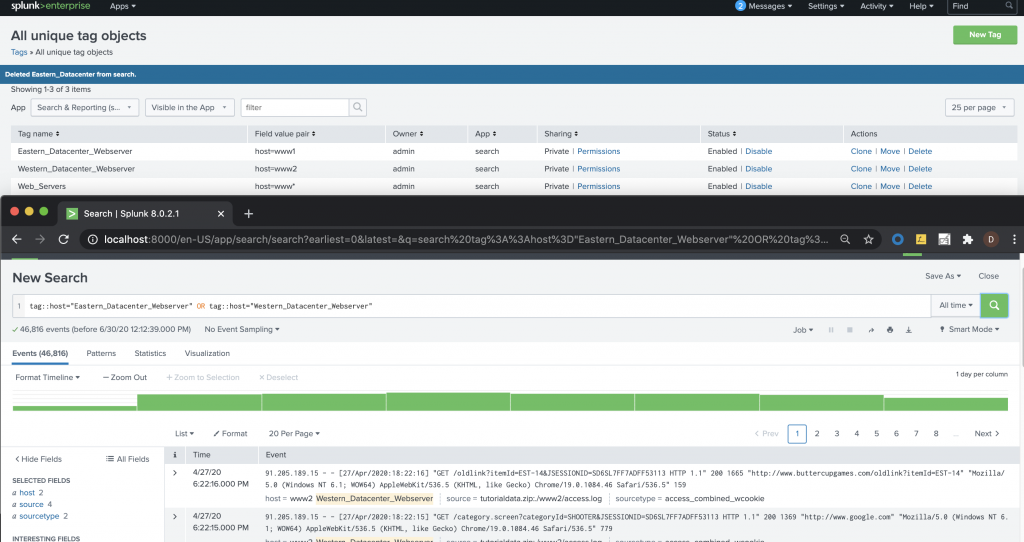
Figure 1 – Sample tagging in Splunk
Technical Add-ons
Finally, let’s throw in technical add-ons and how they work in tagging to knowledge objects. When you have a known data type coming in, you can implement a technical add-on. This add-on will take the data, ingest it, and apply known rules to it.
We can look at firewalls as an example. If you have a known firewall bender, you can apply the technical add-on for the known firewall bender. By adding a technical add-on, your data is now CIM compliant. The technical add-ons take the data coming in from the firewall, tag it, and perform a field alias.
The technical add-ons use event data and group the data sets by common terms instead of the vendor term. How is this helpful? The ability to search by common terms allows for easier communication flow across teams. Common terminology, via the Common Information Model (CIM), helps with communication across vendors and teams.
If you found this helpful…
You don’t have to master Splunk by yourself in order to get the most value out of it. Small, day-to-day optimizations of your environment can make all the difference in how you understand and use the data in your Splunk environment to manage all the work on your plate.
Cue Atlas Assessment: a customized report to show you where your Splunk environment is excelling and opportunities for improvement. Once you download the app, you’ll get your report in just 30 minutes.



