

What exactly is data sprawl in splunk? Data sprawl isn’t really a technical term you’ll find in the Splexicon (Splunk’s glossary). Here at Kinney Group, however, we’ve been around Splunk long enough to identify and define this concept as a real problem in many Splunk environments. Data sprawl is usually not one single thing you can point to, but rather a combination of symptoms that generally contribute to poorly-performing and difficult-to-manage Splunk implementations. We will examine three of the symptoms we use to define data sprawl, and break down the impacts to your organization:
- Ingesting unused or unneeded data in Splunk
- No understanding of why certain data is being collected by Splunk
- No visibility into how data is being utilized by Splunk
Ingesting unused or unneeded data in Splunk
When you ingest data you don’t need into Splunk, the obvious impact is on your license usage (if your Splunk license is ingest-based). This may not be your highest concern if you aren’t pushing your ingest limits, but there are other impacts that can impact your environment.
To begin with, your Splunk admins may be wasting time managing this data. They may or may not know why the data is being brought into Splunk, but it’s their responsibility to ensure this happens reliably. This is valuable time your Splunk admins could be using to achieve high-value outcomes for your organization rather than fighting fires with data you may not be using. Atlas Data Management assists Splunk administrators ingest data into Splunk and manage it through its lifecycle.
Additionally, you may be paying for data ingest you don’t need. If you’re still on Splunk’s ingest-based pricing model, and you’re ingesting data you don’t use, there’s a good chance you could lower Splunk license costs by reducing your ingest cap. In many cases, we find that customers have license sizes higher than they need to plan for future growth.
We commonly run into scenarios where data was being brought in for a specific purpose at one point in the past, but is no longer needed. The problem is that no one knows why it’s there, and they’re unsure of the consequences of not bringing this data into Splunk. Having knowledge and understanding of these facts provides control of the Splunk environment, and empowers educated decisions.
No understanding of why certain data is being collected by Splunk
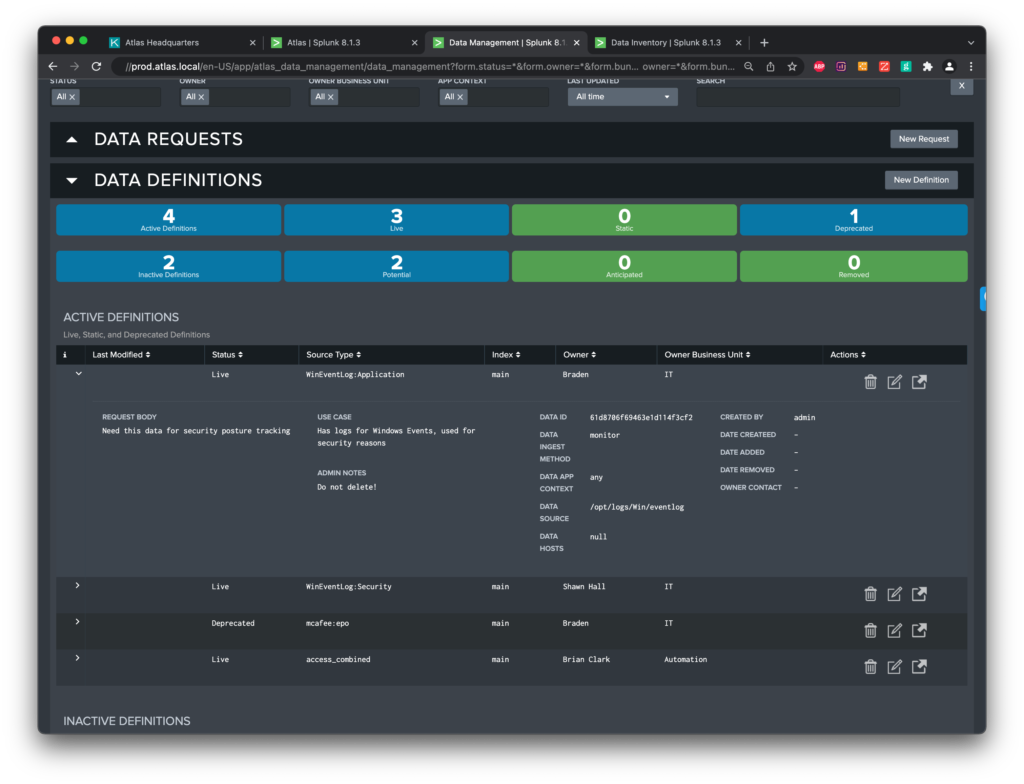
Another common symptom of Data Sprawl is a lack of understanding around why certain data is being collected by Splunk in your environment. Having the ability to store and manage custom metadata about your index and sourcetype pairs — in a sane and logical way — is not a feature that Splunk gives you natively. Without this knowledge, your Splunk administrators may struggle to prioritize how they triage data issues when they arise. Additionally, they may not understand the impact to the organization if the data is no longer is coming in to Splunk.
The key is to empower your Splunk admins and users with the information they need to appropriately make decisions about their Splunk environment. This is much more difficult when we don’t understand why the data is there, who is using it, how frequently it is being used, and how it is being used. (We’ll cover that in more detail later.)
This becomes an even bigger issue with Splunk environments that have scaled up quickly. As time passes, it becomes easier to lose the context, purpose, and understand the value of the data in your Splunk environment. The Atlas Data Management module in the Atlas Platform helps you maintain control of your data sources.
Common Issue
Let’s consider a common example we encounter at Kinney Group.
Many organizations must adhere to compliance requirements related to data retention. These requirements may dictate the collection of specific logs and retaining them for a period of time. This means that many organizations have audit data coming in to Splunk regularly, but that data rarely gets used in searches or dashboards. It’s simply there to meet a compliance requirement.
Understanding the “why” is key for Splunk admins because that data is critical, but the importance of the data to end users is likely minimal.
(If this sounds like your situation, it might be time to consider putting that compliance data to work for you. See how we’re helping customers get value from their compliance data today with Atlas.)
No visibility into how data is being utilized by Splunk
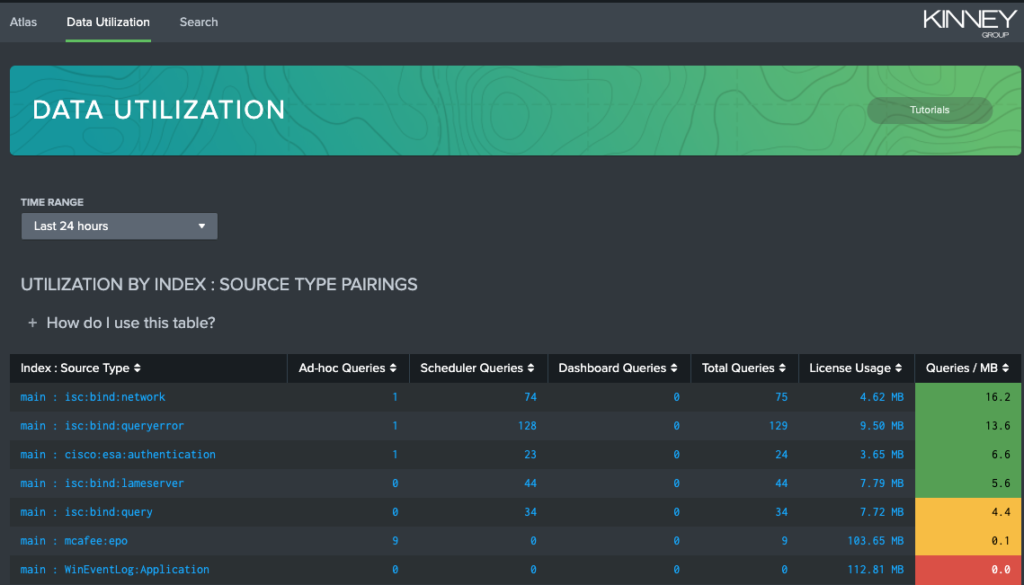
You spend a lot of time and energy getting your data into Splunk. If you don’t understand how and why it is being used this can lead to unnecessary ingest, which is another common symptom of Data Sprawl. Making important decisions about how you spend your time managing Splunk is often based on who screams the loudest when a report doesn’t work. But do your Splunk admins really have the information they need to put their focus in the right place? When they know how often a sourcetype appears in a dashboard or a scheduled search, they have a much clearer picture about how data is being consumed.
Actively monitoring how data is utilized within Splunk is extremely important because you can understand how to effectively support your existing users and bring light to what Splunk calls “dark data” in your environment. Dark data is all of the unused, unknown, and untapped data generated by an organization that could be a tremendous asset if they knew it existed.
Conclusion
Most organizations may not realize that Data Sprawl is impacting their Splunk environment because it doesn’t usually appear until something bad has happened. While not all symptoms of Data Sprawl are necessarily urgent, they can be indicators that a Splunk environment is growing out of control. If these symptoms go unchecked over a period of time they could lead to bigger, more costly problems down the line.
Knowledge is power when it comes to managing your Splunk environment effectively. Kinney Group has years of experience helping customers keep Data Sprawl in check. In fact, we developed the Atlas platform for just this purpose. Atlas applications are purpose-built to keep Data Sprawl at bay (and a host of other admin headaches) by empowering Splunk admins with the tools they need.
Click here to learn more about the Atlas platform, to get a video preview, schedule a demo, or for a free trial of the platform.


