

Data models are useful tools in Splunk because they not only make searching faster, they also excel at searching over many different data sets. Data models are also important for security teams because Enterprise Security (ES) populates and runs on data models. By optimizing your data models, your ES will operate more smoothly.
How Data Models Work in Splunk
One advantage of data models is the ability to combine various source types into a common model by utilizing field aliases. While vendors such as Cisco, Juniper, and Palo Alto may develop products with similar roles, their devices often log in different formats.
The Splunk Data Models in the Splunk Common Information Model (CIM) utilize common field names for searching events regardless of the original vendor or format. A Splunk Add-on for any proprietary log format may comply with the CIM by defining field aliases and tags. The CIM Data Models then pull in the logs from various vendors and sourcetypes by utilizing a simple Splunk query with the appropriate tags.
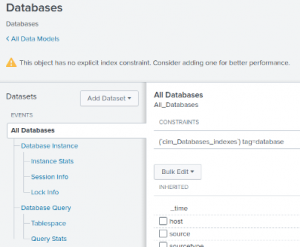
Splunk Data Model Acceleration
Data models can be accelerated or un-accelerated. Accelerated data models require more data and local storage to accelerate a data model and it accelerates only a specific time range of data. The reason data models can be accelerated and pull data more quickly is because they only store the data you need them to, rather than storing fields you don’t need to search and see.
When particular reports are used frequently in Splunk, report acceleration can be useful for improving report load time and reducing duplicate indexer activity. Similarly, certain sets of data may be frequently utilized for a variety of reporting. Similar to Report acceleration, Data Model acceleration provides faster search performance and reduces duplicate activity by your indexers. A variety of reports can be run against the accelerated Data Model without pulling the results from your raw logs each time.
Data Models and Pivot Searches
Splunk searches extract valuable information from your data, but Splunk Processing Language (SPL) can be hard to learn for some users. Data Models provide a benefit for these users in the form of Pivot searches. Splunk’s Pivot search allows you to search without using an SPL query. You can table results using both column or row splits and statistics functions such as sum or average.
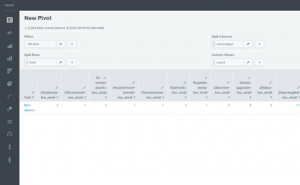
This pivot search can now be converted to many of the standard Splunk visualizations such as a column chart.
How to Create a Data Model in Splunk
Step 1: Define the root event and root data set.
The first step in creating a Data Model is to define the root event and root data set. The root data set includes all data possibly needed by any report against the Data Model. For example, the Web Data Model:
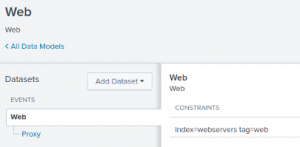
Step 2: Define child data sets.
Additionally, you can define child data sets so that you can search smaller subsets of your data. For instance, you can search the “proxy” child dataset of the Web Data Model.
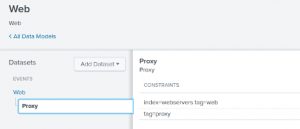
After creating one or more datasets, you can then add fields to your Data Model. While entire raw events are stored in your Splunk indexes, Data Models only store the fields you specify.
You can add fields from eval expressions, lookups, regular expressions, or automatic field extractions. Your child datasets inherit the fields of their parents while optionally having their own additional fields.
Data Model… Done!
And there you have it! A quick breakdown of Data Models and how they can take your Splunk efficiency to the next level. After defining your root data, child data, and fields – creating your data model gives you a completely new set of eyes on your data. From this lesson, you can take away tips on how to improve search performance and speed up the report processing time.
Splunk Pro Tip: There’s a super simple way to run searches simply—even with limited knowledge of SPL— using Search Library in the Atlas app on Splunkbase. You’ll get access to thousands of pre-configured Splunk searches developed by Splunk Experts across the globe. Simply find a search string that matches what you’re looking for, copy it, and use right in your own Splunk environment. Try speeding up your searches right now using these SPL templates, completely free.

Run a pre-Configured Search for Free
If you found this helpful…
You don’t have to master Splunk by yourself in order to get the most value out of it. Small, day-to-day optimizations of your environment can make all the difference in how you understand and use the data in your Splunk environment to manage all the work on your plate.
Cue Atlas Assessment 30-day free trial: a customized report to show you where your Splunk environment is excelling and opportunities for improvement. You’ll get your report in just 30 minutes.



