
Cluster Bundles are packages of knowledge objects that must be shared between indexers and search heads in clustered environments. Unfortunately, these can get too big and cause performance issues for your Splunk environment. We’ve discovered a trick that can drastically reduce Splunk cluster bundle size for optimal performance, while maintaining operations, and improving performance! Strangely enough, this method is barely mentioned in Splunk Docs. It’s a hidden feature we need to share!
Bundles of Awesome!
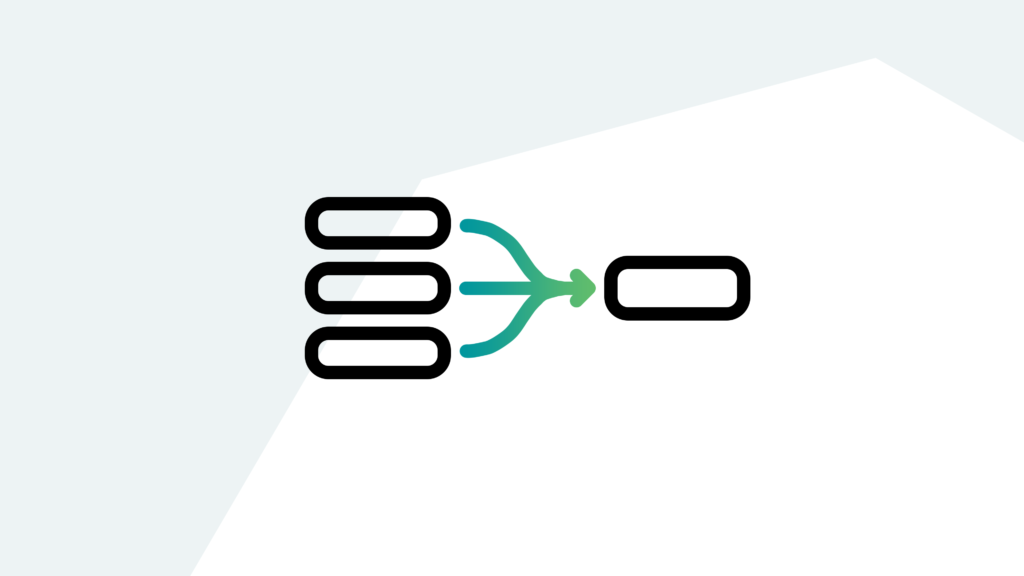
The modern Splunk deployment has clustered Indexers and Search Heads that help share the load of reading, searching, and computing data for users and alerts, every second of the day. These separate instances communicate with each other to properly execute tasks and keep things running as smoothly as possible — but what happens when a user makes a change on one instance? It needs to waterfall down to the many other pieces in the Splunk architecture, and it does that using Splunk Bundle Replication.
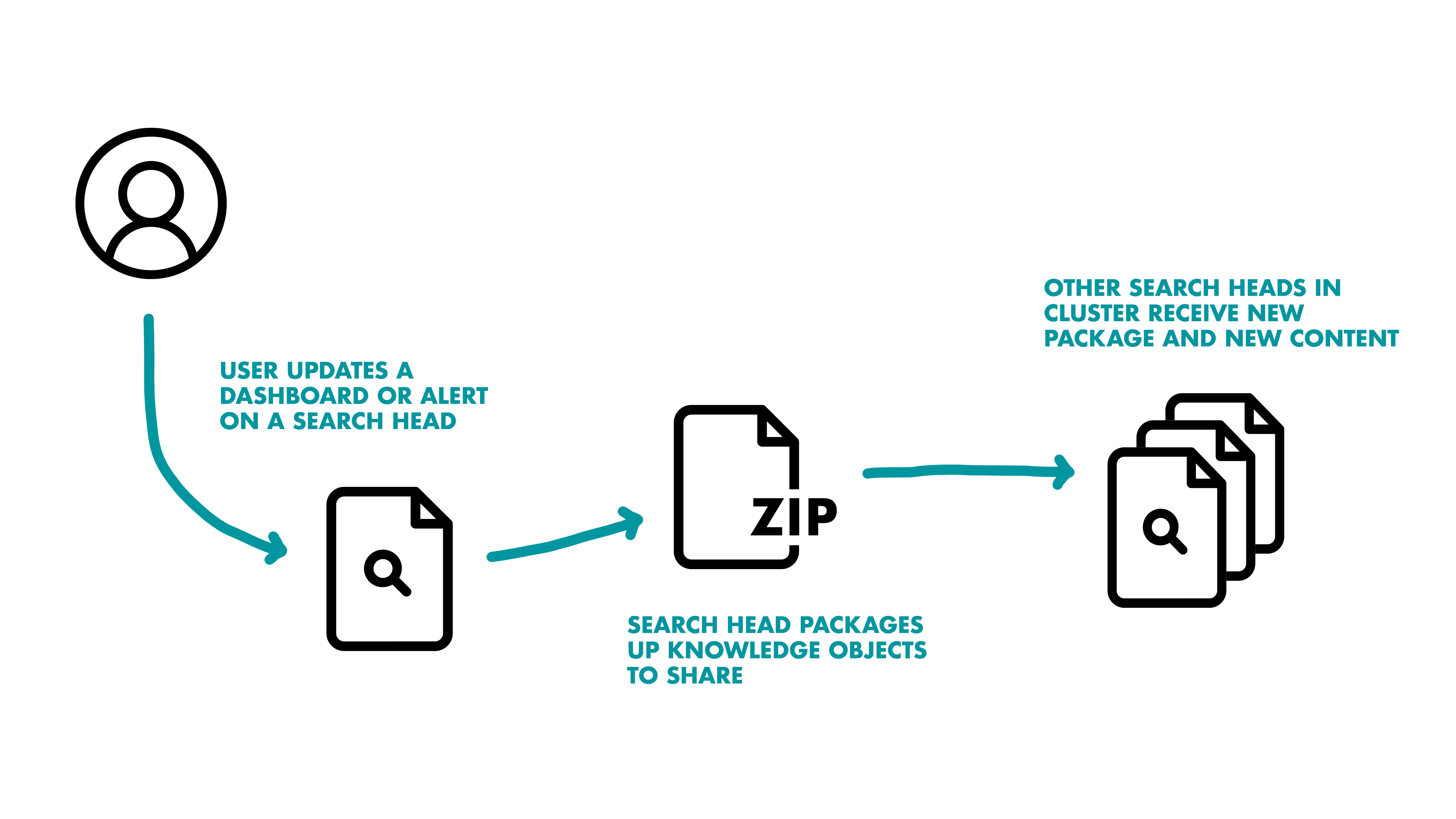
This usually works great! Users edit items, the Search Heads and Indexers share information, and everything stays relatively up to date and actionable for users. However, when its functionality is pushed to its limits, both Splunk Admins and Users will experience a headache like none other.
A Bundle of Pain!
In mature Splunk ecosystems, this bundle system can start tripping over itself and quickly cause issues downstream. Having Knowledge Objects which are too big (or having too many) can cause replication errors, leading to search slowdowns for users, Search Heads spending precious CPU managing large files instead of search execution, and updates failing to be shared between Splunk instances. All these errors are the fast lane to Splunk instability (and a royal pain).
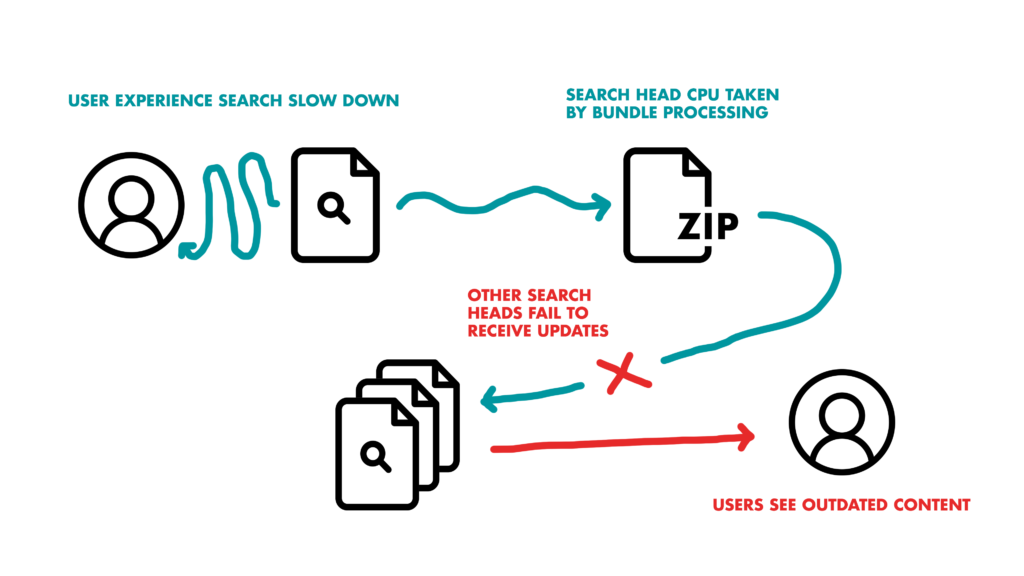
If only there was “one weird trick” to alleviate your bundle sized pain and prevent these issues!
One Weird Trick!
Surprise, surprise — there is! One cause of large bundle sizes is big lookup files your Splunk system creates and relies on for quick referencing. Unlike dashboards or other Knowledge Objects, however, lookups can get big and unwieldy, leading to your bundle size growing and growing.
Fortunately, this “hidden trick” we’re talking about can reduce the size of your lookups, and greatly reduce your bundle size. This trick? Compression!
Splunk Pro Tip: This type of work can be a considerable resource expense when executing it in-house. The experts at Kinney Group have several years of experience architecting, creating, and solving in Splunk. With Expertise on Demand, you’ll have access to some of the best and brightest minds to walk you through simple and tough problems as they come up.
Compress your Problems!
Splunk supports lookup compression, enabling Admins to convert their lookups to a much more reasonable size. If done right, there will be no usability difference! Follow the steps below to compress your largest lookups and fix your bundle size!
- Identify a large lookup file you would like to compress to reduce your bundle size
- Navigate to that file in the Command Line Interface of the system
- Gzip the lookup file (gzip largelookupfile.csv)
- Searches of these compressed lookups will now need to include a .gz, unless you create a lookup definition that uses the original lookup name, mapped to the new file.gz name!
That’s it! With this workflow, you can reduce the size of lookups by around 50%, and potentially reduce your bundle size by around 30% or more! All the while, your users’ searches and dashboards will operate the exact same, except for being error free. Compressed lookups can still be edited using outputlookup, and can of course be referenced using the lookup command.


