

The Splunk platform REST API provides the ability to create, read, update, or delete resources across the Splunk Enterprise platform. This capability can be leveraged to query, configure, and even run searches in your Splunk environment programmatically utilizing client software based on the popular programming languages C#, Java, JavaScript, or Python, and you can even run REST commands from the Splunk Web Search bar or your browser address bar.
It may be interesting to note that almost without exception every activity performed in Splunk Web or any Splunk command executed from a command line will result in an API call to the splunkd daemon – which gives you some idea of the coverage and power of the API endpoints.
This article will explain what the Splunk REST API is all about, how it works, the key concepts you need to know to use it. We’ll also provide several use cases and examples you can easily duplicate to take advantage of this powerful feature.
What is the Splunk REST API?
A REST (Representational State Transfer) API (Application Programming Interface) is a way for computer programs to exchange information in a structured, standardized fashion. A term that is commonly associated with API discussions is ‘endpoint’, which is simply the URL utilized to contact a server or service and specify which information is being accessed. For example, the API endpoint URL to obtain basic information about a Splunk server is:
https://localhost:8089/services/server/info
This URL will return a list of Splunk applications installed on this server:
https://localhost:8089/services/apps/local
You can see from the differences in the above examples that the various API ‘endpoints’ for accessing data are simply the different URL paths to those resources.
Splunk REST API Concepts
In addition to endpoints, there are several other concepts that you should be familiar with when working with the Splunk REST API. A key concept is that of ‘CRUD’, which is an acronym that represents the types of operations or ‘methods’ you can use with an API: Create, Read, Update, and Delete. These methods are available in Splunk API HTTP calls as:
- GET [Read] – read the current resource state, or if the endpoint represents a collection, list the members of the collection.
- POST [Create/Update] – create a resource or update existing resource data.
- DELETE [Delete] – delete an endpoint from the resource hierarchy.
Another set of concepts that are key to working with many of the Splunk API endpoints is ‘eai:acl’, which you’ll see in the output of most Splunk API calls. The ‘eai’ part stands for ‘Enterprise Application Integration’, which is an industry standardized framework to enable different systems and applications across an enterprise to exchange data – basically, a universally accepted data exchange format. The other part – ‘acl’ – stands for ‘Access-Control List’, which is a list of relationships and permissions associated with a system resource (endpoint object). An ACL specifies which users or system processes are granted access to specific endpoint objects and what operations are allowed on those objects. The ‘eai:acl’ portion of Splunk API results is simply an access control list in EAI format.
Related to the Access Control List is the concept of ‘namespace’, which in the context of Splunk refers to the use of an ‘owner’ (often a username) and ‘app’ when specifying a resource. Some resources don’t require that you reference a namespace, such as when you request information about a Splunk server with the /services/server/info endpoint. But if you’re querying Splunk to retrieve the saved searches associated with a given Splunk app (which are stored in a savedsearches.conf file within that app), you must specify the app in the URL because there can be saved searches in multiple Splunk apps and Splunk needs to know which one you’re referencing. In like fashion, you must specify the owner of a resource because if the permissions for a given saved search are set to ‘private’, the saved search content actually resides in a ‘user’ folder, not in the /etc/apps/<app> folder.
Every Splunk resource belongs to a namespace. The namespace is specified by an owner and app and is governed by a sharing mode which you’ll recognize from the ‘permissions’ settings on Splunk knowledge objects such as alerts, dashboards, reports, etc. The possible values for sharing are: “user”, “app”, “global” and “system”, which map to the following combinations of owner and app values:
“user” => {owner}, {app} “app” => nobody, {app} “global” => nobody, {app} “system” => nobody, system
“nobody” is a special username that basically means ‘no user’ and “system” is the name reserved for system resources.
Creating a URL to access a Splunk resource which requires specifying an owner and app requires utilizing the /servicesNS/ attribute (vs /services/), which switches the server to namespace-aware mode. For example, the URL for accessing the saved searches in the ‘search’ app that are available within the app or globally is:
https://localhost:8089/servicesNS/nobody/search/saved/searches
In some cases, you can negate use of the owner and/or app by using a hyphen:
https://localhost:8089/servicesNS/-/-/search/jobs
The last concept you should be aware of when using the SPLUNK API is that of the ‘Splunk Atom Feed’, which you will see referenced in the results when making an API call to a Splunk resource. This reflects Splunk’s use of the ‘Atom Publishing Protocol’, which is a protocol for performing CRUD (Create, Read, Update, Delete) operations over HTTP. Related to this is the ‘Atom Syndication Format’, which is the most commonly used portion that defines the XML schema (format) used to deliver data during a Read operation.
Don’t allow all this formalized language to become too daunting – we can easily wrap these topics up into just the parts you really need to understand when working with the Splunk REST API. An example should help – you can paste this URL into the browser address bar on a Splunk instance you are logged into:
https://localhost:8089/servicesNS/nobody/search/saved/searches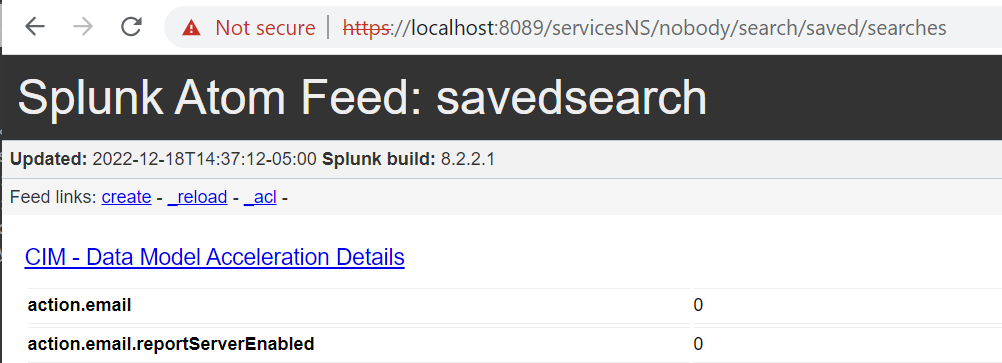
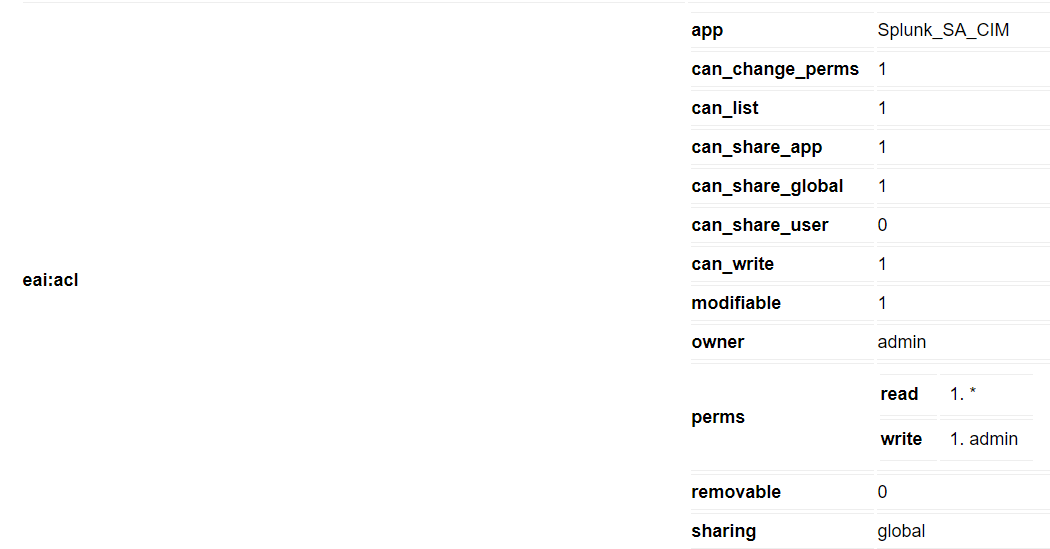
For each resource listed in the output there is an ‘eai:acl’ section which specifies the app, owner, and various sharing / permissions settings:
If you run a cURL command from a terminal session on this server, you will receive the same results in XML (you must provide an authentication username and password):
curl -k -u admin:password https://localhost:8089/servicesNS/nobody/search/saved/searches
When you inspect the results of this API call, the format of the XML output is the schema based on the Atom Syndication Format. Spend some time looking through this output, noting the use of hierarchical dictionaries and key-value pairs, and it will (eventually) become familiar. The excerpt below reflects the eai:acl section which can be compared to the table version depicted above:
<s:key name="eai:acl"> <s:dict> <s:key name="app">Splunk_SA_CIM</s:key> <s:key name="can_change_perms">1</s:key> <s:key name="can_list">1</s:key> <s:key name="can_share_app">1</s:key> <s:key name="can_share_global">1</s:key> <s:key name="can_share_user">0</s:key> <s:key name="can_write">1</s:key> <s:key name="modifiable">1</s:key> <s:key name="owner">admin</s:key> <s:key name="perms"> <s:dict> <s:key name="read"> <s:list> <s:item>*</s:item> </s:list> </s:key> <s:key name="write"> <s:list> <s:item>admin</s:item> </s:list> </s:key> </s:dict> </s:key> <s:key name="removable">0</s:key> <s:key name="sharing">global</s:key> </s:dict> </s:key>
The Benefits of using the Splunk REST API
One of the benefits of using the Splunk REST API is that it provides the ability to query and manage Splunk resources programmatically and remotely. Client software can leverage the various API endpoints independent of the Splunk server locations, across a whole range of servers.
Another benefit of using any REST API is that it relies on the HTTP standard, which means it is format agnostic such that you can use XML, JSON, HTTP, etc. to query and manage resources utilizing readily available libraries in a variety of programming libraries, keeping the solution lightweight and flexible. Encoding scheme examples available with the Splunk API include:
- csv
- json
- json_cols
- json_rows
- raw
- xml
Finally, as stated before, all Splunk resources can be fully managed utilizing the various REST API endpoints available. Endpoint responses are performant and provide an extensive amount of object-specific information and control in one API call, making this a very powerful option for managing a Splunk environment.
Types of Splunk REST APIs
The Splunk REST API endpoints are grouped into the following categories, which together constitute the entire spectrum of Splunk resources:
- Access control
- Authorize and authenticate users.
- Applications
- Install applications and application templates.
- Clusters
- Configure and manage indexer and search head clusters.
- Configuration
- Manage configuration files and settings.
- Deployment
- Manage deployment servers and clients.
- Inputs
- Manage data input.
- Introspection
- Access system properties.
- Knowledge
- Define indexed and searched data configurations.
- KV store
- Manage app key-value store.
- Licensing
- Manage licensing configurations.
- Outputs
- Manage forwarder data configuration.
- Search
- Manage searches and search-generated alerts and view objects.
- System
- Manage server configuration.
- Workload Mgmt
- Manage system resources for search workloads.
Some endpoints are only applicable to Splunk servers that provide specific functions – the Licensing configuration endpoints are only relevant to a node performing the License Manager function, for example.
To see a list of all available endpoints and operations for accessing, creating, updating, or deleting resources, see the REST API Reference Manual.
How to Use the Splunk Rest API
As seen in previous examples, you can query Splunk REST API endpoints utilizing the address bar in your browser, or by utilizing properly formatted cURL commands from a terminal session.
You will need to authenticate to the API endpoint, which requires having role and/or capability-based authorization to use REST endpoints for various resources. The admin user inherits all the credentials needed to access Splunk API endpoints.
The default output mode for a cURL or programmatic API call is XML. You can add ?output_mode=json to the end of a URL path to have Splunk return the data in JSON format:
curl -k -u admin:password https://localhost:8089/servicesNS/nobody/search/saved/searches?output_mode=json
You can also specify csv, raw, or json_cols or json_rows output modes for some endpoints where those formats make sense.
Note that while the browser address bar REST call examples provided in previous sections have included ‘localhost’ in the URL, you can specify the IP address and API endpoint port (typically 8089 for Splunk) in the browser address bar to query data from remote servers (if you have network and server access).
You can also utilize the ‘rest’ SPL command in the Splunk Search bar to query API endpoints on the local Splunk server that you are logged into (not a remote server), and then use the | table command to display just the fields you are interested in:
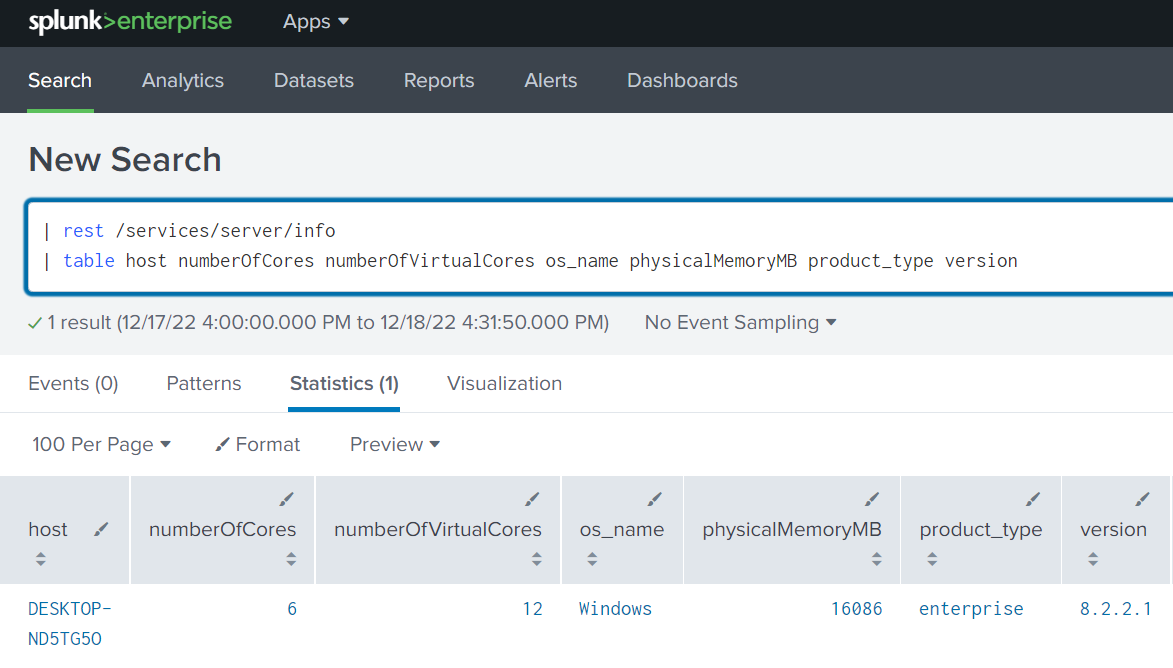
You can also send data to Splunk using a HTTP Event Collector (HEC) API event or raw endpoint, including the HEC token to accomplish authentication. The ‘event’ endpoint expects data sent in JSON format:
curl -k https://127.0.0.1:8088/services/collector/event -H "Authorization: Splunk 0ca3f923-371f-478e-8bfe-264b0b5dc17d" -d "{\"sourcetype\": \"demo\", \"event\":\"Hello, world!\"}"
Once you run the curl command you should get the following response:
{”text”:”Success”, ”code”:0)
You can then search for this event in Splunk – this is an excellent way of testing HEC endpoints:
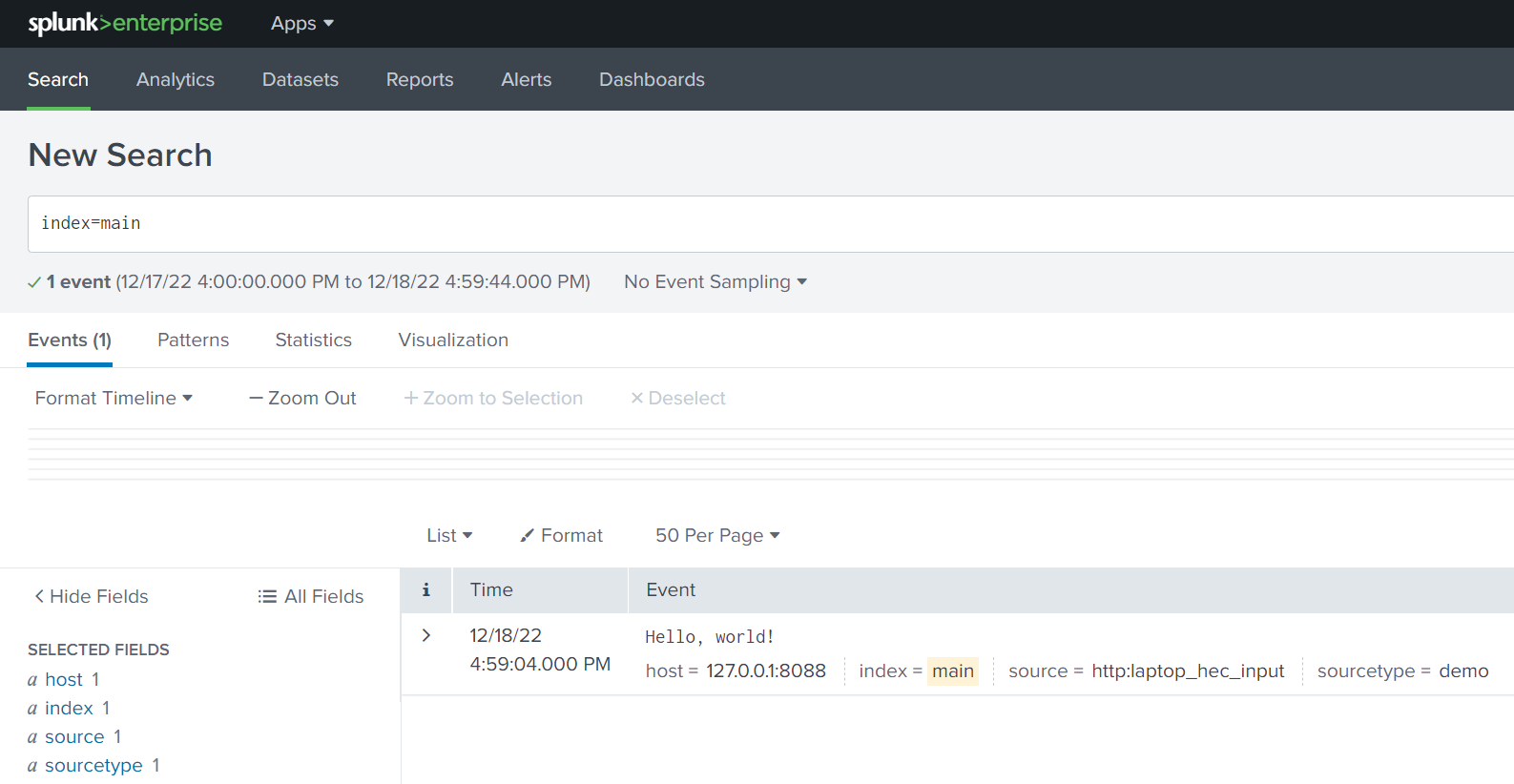
So far, the discussion and examples have centered on address or search bar and cURL commands. But the real power of the Splunk REST API is evident when utilizing it to monitor, query, and manage an entire Splunk environment programmatically, or using data from Splunk in other solutions by building apps and integrations that leverage its API capabilities. A discussion of how this is done is beyond the scope of this article, but you can explore this capability by perusing the Splunk Developer site, which provides a wealth of information about how to set up your development environment, develop and test Splunk apps, and links to all the Splunk Enterprise SDKs for Python, Java, JavaScript, and C#.
https://dev.splunk.com/enterprise/docs/welcome
Splunk REST API access on Splunk Cloud
You can use a limited subset of the Splunk Enterprise REST API endpoints with your Splunk Cloud Platform deployment. You might need to take extra steps to access your Splunk Cloud Platform deployment for using the Splunk REST API and SDKs, using of the following options:
- Use the Admin Config Service (ACS) API search-api/ipallowlists endpoint to add IP addresses to the search-api allow list.
- Submit a support case requesting access using the Splunk Support Portal. Splunk Support will open port 8089 for REST access.
See the Splunk documentation for more information on Splunk Cloud API access.
Use Case Examples for the Splunk REST API
In addition to the examples provided in the previous sections, the following are some more useful Splunk REST API endpoints for working with your Splunk deployment. Using the | rest command in a Splunk Web Search bar with some of the top-level API endpoints will provide a list of the underlying endpoints, making it easier to locate data of interest.
/services/server
List of endpoints for Splunk server info endpoints
/services/server/health
Splunk server health – the same data as in the Health icon
/services/search/
List of endpoints for Splunk search
/services/search/jobs
See a list of recent completed search jobs
Some endpoints will require use of the /servicesNS/{app}/{owner}/{endpoint} method:
/servicesNS/nobody/search/saved/
/servicesNS/nobody/search/saved/searches
/servicesNS/-/-/search/jobs
In some cases the owner/app doesn’t matter – explore!
Of course, the most powerful use of the Splunk REST API is leveraging Splunk Enterprise SDKs that provide a wrapper over the REST API endpoints for writing applications that programmatically interact with the Splunk platform. Using a minimum of additional code, you can write applications that fulfil business use case objectives and extract the most value out of a Splunk Enterprise deployment:
- Search your data, run saved searches, and work with search jobs
- Manage Splunk configurations and objects
- Integrate search results into other applications
- Send log data directly to Splunk Enterprise
- Develop a custom UI for working with Splunk resources
Conclusion
The Splunk REST API is a powerful portal for monitoring, querying, and managing Splunk Enterprise resources, extracting data from Splunk for other applications, and building custom solutions that leverage the data collection and analytics capabilities of a Splunk Enterprise environment.
This article explained what a REST API is, the most important concepts and benefits of using the Splunk REST API and provided explanations and examples of how to use it in several contexts. I hope this has provided a foundation that you can use to explore the Splunk API in more depth on your own and use it to create exciting, powerful solutions for working with your Splunk data.
If you found this helpful…
You don’t have to master Splunk by yourself in order to get the most value out of it. Small, day-to-day optimizations of your environment can make all the difference in how you understand and use the data in your Splunk environment to manage all the work on your plate.
Cue Atlas Assessment: Instantly see where your Splunk environment is excelling and opportunities for improvement. From download to results, the whole process takes less than 30 minutes using the button below:



